Сергей Гордейчик с конца прошлого века интересуется разработкой, белошляпным хакерством, развитием технологий и бизнеса. Работал в РЖД, "Лаборатории Касперского", был CTO и замом гендиректора Positive Technologies. Сейчас увлекается AI, живёт в Дубаи, работает в Абу Даби, преподаёт в барселонском университете Harbour.Space.
В последнее время в Интернете наблюдается всплеск дискуссий вокруг одного из элементов развития искусственного интеллекта (ИИ) и технологий машинного обучения, а именно – обработки данных. К сожалению, это в целом правильное и полезное обсуждение приводит к предложению очередного капитального строительства дата-центров.
Эта мысль подкрепляется тенденцией "импортозамещения", только вместо "отечественной операционной системы" на первый план выходят "российские ИИ-процессоры" и рассуждения о том, что у нас холодно и достаточно электроэнергии, поэтому строить специализированные дата-центры с ИИ – это хорошо и полезно.
Зачем же строить отдельные дата-центры для ИИ? В целом – пока незачем… Пока под это не будет специальных задач, пока это не востребовано рынком, конкретными заказчиками. Дата-центры – это далеко не цель, а средство. Более того, средство не первой необходимости. Сами по себе дата-центры не смогут стать драйвером или серьезным помощником в области развития ИИ.
А что сможет?
Данные – новое золото
В чем же причина этой дискуссии? Существует расхожая мысль, что "топливом" для ИИ и машинного обучения являются данные, и что не бывает плохих моделей, бывает недостаточно данных. Постулат "чем больше данных, тем лучше" работает, но с некоторыми допущениями, на которых мы остановимся позже. В своей популярной книге "Сверхдержавы искусственного интеллекта" известный китайский бизнесмен Кай-Фу Ли, сравнивая подход США и Китая, определенно заявляет, что одним из серьезных конкурентных преимуществ Китая является огромное количество данных, которые можно собрать за счет большого населения, и внедрения в повседневную жизнь технологий (IoT, мессенджеры, мобильные платежи и проч.), собирающих все эти данные "в облаке".
Таким образом, одной из причин возникновения дискуссии о построении дата-центров для ИИ является необходимость сбора, централизованного хранения и обработки больших объемов информации.
Следующей причиной дискуссии является тот факт, что многие виды данных, которыми "кормится" наш ИИ, защищены законодательно. В частности, это могут быть банковские данные – информация об операциях, счетах и вкладах (банковская тайна). Это могут быть данные о состоянии здоровья и диагнозе (медицинская тайна), и целый букет других тайн, начиная с персональных данных, определяемых в 152-ФЗ, и заканчивая 65 другими видами тайн (.pdf), которые при большом желании можно насчитать в нашем законодательстве.
В связи с этим возникает вопрос: а как эти данные обрабатывать? К некоторым данным государство по закону имеет доступ. Но частным организациям эту информацию получать дорого, сложно и некомфортно. И даже если какой-то удачей их удастся одномоментно заполучить, эти данные будут фрагментарными, не обновляемыми, что для обучения моделей ИИ плохо. Об этом сейчас много говорят на самом высоком уровне и, видимо, в ближайшем будущем нас ждут серьёзные изменения в области защиты персональных данных. С другой стороны, возникает сообщество противников такой либерализации, уже начавших поминать "Число зверя".
Трудно не согласиться, что вся эта история с ИИ сильно попахивает серой, достаточно вспомнить Лема с "Сотворением миров" и прочей демиурговщиной как пределом развития "Суммы технологий".
Порочный круг обработки данных
Давайте попробуем спуститься в этой дискуссии с общественно-политического уровня на уровень производственно-технический.
Прежде чем перейти к деталям, давайте посмотрим на схему на рисунке 1 (Cross-industry standard process for data mining, CRISP-DM, во многом схож с ISO/NP TR 23347) и прекрасно подходит для описания процесса разработки систем ИИ, особенно Narrow Artificial Intelligence (узкоспециализированный ИИ).
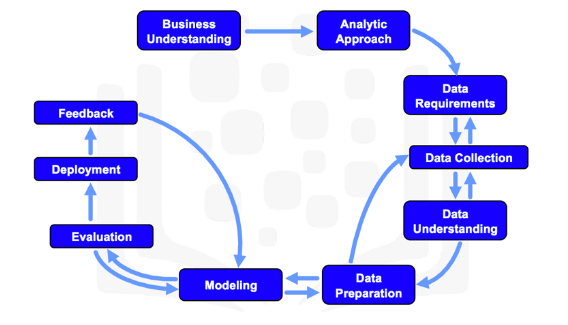
Рис.1 Межотраслевой стандартный процесс для исследования данных
На схеме видно, что половина всех этапов создания таких систем, относятся к данным. В зависимости от системы, которую вы разрабатываете, затраты на активности, связанные с данными, могут составлять до 50% всего бюджета, а иногда и выше.
Очень схожим образом процесс разработки моделей визуализирован на схеме "Пирамида потребностей науки о данных".
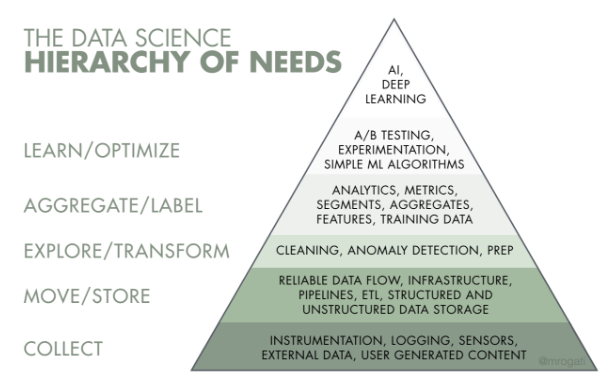
Рис.2 Пирамида потребностей машинного обучения
На обоих схемах видны этапы, которые нужно пройти прежде, чем обучать модели, для чего, естественно, потребуется подключать те самые "российские ИИ-процессоры". Что же это за этапы? Первый этап – это непосредственно получение данных.
Собрать их всех
Предположим вы – стартап в области ИИ с отличными идеями. Вам нужно где-то взять исходные данные. Например, вы разрабатываете систему компьютерного зрения, анализирующую компьютерную томографию (КТ) легких для выявления патологий. У вас есть необходимость в десятках тысяч КТ/НДКТ. Где их можно взять? По некоторым направлениям, например по тем же КТ, сложилась относительно хорошая ситуация – существуют открытые датасеты, бери и обучай. В чем минусы? Открытые датасеты известны всем. Это базовый уровень, который есть у всех ваших конкурентов. Качество моделей не определяется, но в высокой степени зависит от тех данных, на которых проходило обучение. К тому же если вы берете данные от отличающейся системы радиологии (азиатской или американской), то в результате вы не можете гарантировать адекватность обработки вашей моделью локальных результатов. Таким образом, вам нужно раздобыть "свои" данные. Входить в контакты с различными медицинскими учреждениями, делать совместные исследования, давать им свою систему бесплатно (со скидками), покупать данные (что затратно и не всегда соответствует законодательству, см. выше).
Второй момент: часто прорывные идеи, технологии ИИ появляются в смежных областях. Предположим, вы все тот же медицинский стартап, и у вас есть идея связать случаи заболевания, выявляемые вашей системой, с географией и с наследственной предрасположенностью. Но этих данных у ваших медицинских контрагентов нет, а если есть – то их достаточно сложно обезличить. Придется искать новые источники данных. И такая проблема касается не только стартапов, но и больших организаций.
Если вдруг окажется, что модель, выявляющая финансовый фрод, прекрасно подходит для выявления мошенничества в сетях энергораспределения или газоснабжения, как об этом узнает "Газпром" или "РАО ЕС"?
Даже банкам, которые хотят использовать систему распознавания лиц, приходится покупать данные или даже целиком компании, занимающиеся данным вопросом. А также нужно проводить большую работу по сбору личной информации и биометрических данных, по работе с людьми, чтобы они эту информацию отдавали (здесь примерно миллион ссылок на то, как это делает Сбербанк).
Исходные необработанные данные сами по себе могут быть обузой, занимающей место в хранилищах данных. Что подразумевается под обработкой? К примеру, в системах ИИ в области дистанционного зондирования Земли (ДЗЗ) "сырые" космические снимки (КС), приходящие со спутника, фактически не используются. Исходные КС, как правило, проходят обработку по коррекции искажений датчиков, влияния вращения и кривизны Земли, ортотрансформирование и так далее. Та базовая карта (basemap), которую вы видите на Yandex.Map или Google.Earth, на самом деле клеится из снимков различных спутников, произведенных в различное время и вообще – неправда.
Эта корректировка необходима, потому что обучение и тестирование на разнородных данных даст плохие результаты. Если, конечно, нет задачи построить модель, где условием является использование неоткорректированных данных, но это скорее относится к задачам ВПК.
Аннотируй это
Следующий жизненно необходимый этап, это аннотация, то есть подготовка данных для обучения моделей. И здесь существенную роль играет человек. Если вернуться к тому же примеру с медицинским стартапом, то перед тем, как обучать модель, вам нужно получить аннотированные примеры положительных, и отрицательных результатов КТ, на предмет определения, например, рака легких с сегментацией очагов. Фактически вам необходимо взять десятки тысяч исследований пациентов и вручную разметить очаги. Причем эта разметка должна соответствовать тому результату, который вы хотите получить от модели. Если на выходе представляется bounding box или heatmap (то есть разметка прямоугольником только расположения потенциального узелка или градиентная карта), то и сегментируйте соответствующим образом. Однако, если вы планируете, что ваша система должна выделять трехмерную модель очага (что является сейчас вполне стандартными требованиями для подобных систем), предсказывать плотность, классификацию узелков по BI-RADS, то вам понадобится соответствующая аннотация.
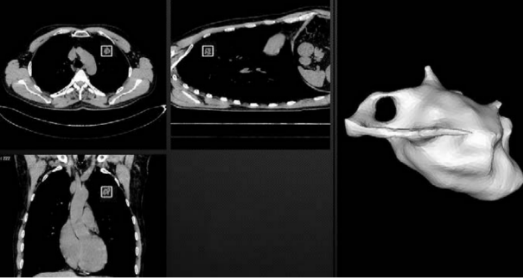
Рис.3 Сегментация опухолевого узелка (слева – bounding box, справа – 3D модель). Источник.
Если отталкиваться от текущего состояния отрасли, то те модели, которые работают сейчас и показывают неплохие результаты, требуют более 40 тысяч подобных размеченных изображений. Сколько это стоит? В общем, разметка одного исследования КТ стоит около $10, но если это разметка с дополнительными условиями (например 3D сегментация) или с кросспроверкой, поскольку есть данность, что врачи имеют право на ошибку, то стоимость может увеличиваться в 2-4 раза. В итоге только для получения базового размеченного набора нашему стартапу требуется около $1M и время, пока врачи-консультанты закончат эту работу.
А нельзя ли использовать клинические данные, историю болезни? Теоретически – да, на практике – крайне редко и в очень специфических случаях. В большинстве случаев диагноз – это запись с свободной, недостаточно структурированной для компьютерных систем форме. И ни одна система распознавания текстов (Natural Language Understanding) адекватно не переведет описание томограмм в координаты и формы новообразования, поскольку там эта информация просто отсутствует.
Подобная ситуация распространяется не только на анализ медицинских изображений. Точно также требуется аннотация и голосовых данных, и текстовых, и более структурированных данных.
Рассмотрим пример оптимизации технологических процессов, в частности – оптимизации энергопотребления и генерации: энергопотребление дата-центра или более глобально - балансировка сетей. Информация, поступающая со всех уровней АСУ ТП – с контроллеров PLC (или PDU в датацентре), со SCADA-систем, может быть достаточно разнородной. Понятно, что в энергетике есть стандарт (IEC 61850). Но, из опыта анализа защищенности и внедрения систем кибербезопасности АСУ ТП сложилась уверенность, что понимание конкретных низкоуровневых данных, которые можно извлечь из систем, требует участия инженерных подразделений и, иногда разработчиков данной системы.
Энергетике еще крупно повезло, за счет наличия стандартов. В других областях (в железнодорожном транспорте, нефтедобывающей, нефтеперерабатывающей и т.п.) соседние станции, скважины или цеха нефтехимического комбината могут кардинально отличаться. То есть нужны люди, которые специализируются в данном технологическом процессе и разбираются именно в данном решении АСУ ТП и привести данные к общему знаменателю.
Ценность аннотации демонстрируется ростом рынка инструментов и связанных услуг. По аналитике портала statista.com оценочная стоимость рынка в ближайшее пятилетие будет расти на 27% в год и составит более $2,2B в 2023.
Данные и протоколы
Таким образом, ценностью являются не данные сами по себе, а данные, которые были собраны, предобработаны и аннотированны, и, что немаловажно, к которым был обеспечен доступ. Что значит "обеспечен доступ"? Дело в том, что в больших объемах данных, о которых мы говорим, нет смысла брать и складывать эту информацию в какую-либо файловую систему или реляционную (нереляционную) базу данных. Как правило, большинство типов данных, о которых идет речь, специфичны, уже упакованы в определенную структуру, поддерживают мета-описания. В качестве примера можно привести стандарт DICOM (Digital Imaging and Communications in Medicine), используемый в медицине, в котором в мета-данных содержится очень много полезной информации, подходящей и для поиска, аннотации, и для обучения модели.
И хранилища для этих данных должны поддерживать именно этот специфический формат данных на уровне приложений. Конкретно для медицины они называются PACS (picture archiving and communication system), широко используются для хранения, поиска, организации доступа, получения данных со сканеров. То же самое можно сказать об АСУ ТП, для них есть SCADA и Historian c зоопарком интерфейсов от ModBus до OPC. Для систем геопространственной аналитики (geospatial analytics) существует GeoTIFF, системы каталогизации КС, аэрофотосемки и связанной информации, поддеживающие промышленные интерфейсы (WebTile Mapping Service (WTMS), Web Map Service (WMS) и т.д.).
Конечно, в идеальной ситуации, система хранения должна обеспечивать доступ к данным в соответствии с теми форматами данных и протоколами, которые являются промышленными стандартами. Кроме понятного для конкретной индустрии или конкретной предметной области механизма доступа к данным, использование подобных систем в качестве хранилищ и данных интерфейсов для обращения к информации дает определенное конкурентное преимущество разработчикам и исследователям в этой области.
Возвращаясь к нашему медицинскому стартапу, он будет работать не с набором абстрактных "дайкомов", которые разработчик нашел в Интернете, а он будет работать с PACS системой по DICOM API, запрашивать изображения, преобразовывать выходные данные и передавать их обратно в систему опять же в формате DICOM и/или HL7, что является необходимым элементом в современных медицинских приложениях. В реальной жизни, если вы создадите модель, которая отлично работает, но не интегрирована с системой PACS через DICOM Gateway, никто с вами работать не будет. Потому что медицинским организациям нужен результат, а результат достигается за счет того, что врач радиолог может работать с этими изображениями, анализировать их, давать обратную связь. А врачи сейчас работают с PACS системами через DICOM Viewer-ы. У них есть система, к которой они привыкли, и они хотят видеть результат предлагаемого вами решения в "своей" системе.
Таким образом изначальное складирование, хранение и обеспечение доступа к данным через специализированные существующие системы дает понятный интерфейс, на который нужно ориентироваться при построении своей системы.
Для это можно использовать уже существующие специальные системы, вопрос в том, насколько они готовы работать с теми объемами данных, которые нужны для ИИ и машинного обучения и сколько это будет стоить? Готовы ли мы закупать AGFA HealthCare Enterprise Imaging в масштабах страны или имеет смысл доработать систему с открытым кодом, например, Orthanc? Что выбрать для хранения геопространственной аналитики? Стоит ли обратить внимание на Airbus DataDoors или все же Scanex Web Catalog прекрасно справится с этой задачей?
Магия глубокого обучения
В этой статье я пропущу такой магический уровень как обучение моделей. Это важный момент в контексте дата-центров и он заслуживает отдельной статьи. Собственно "датацентр для ИИ" с точки зрения капстроя, отличается от обычного только повышенными требованиями к энергопотреблению/охлаждению, меньше 15КВт на стойку там иметь смысла нет, а лучше закладывать 20+, учитывая, что уже сейчас расчетное энергопотребление DGX-2H составляет 12КВт при форм-факторе в 10U.
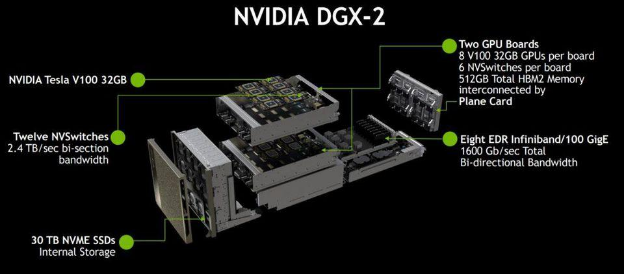
Рис.4. DGX-2. Печка ценой в $400K. Источник nvidia.com
Основные вопросы возникают на оркестрации доступа к этим ресурсам. Думаю, что если бы Сбербанк предоставил облачный доступ к своим GPGPU-серверам, "подорвавшим" рынок майнинга /сарказм/ , это удовлетворило потребности индустрии на несколько лет.
Приятно, что есть и положительные шаги в этом направлении.
Теплое к мягкому
Оценка эффективности работы модели ИИ – нетривиальная задача, особенно для специализированных сценариев. Понятно, что, если ваша модель должна классифицировать изображения собак и кошек, оценить ее работу проще, существует большое количество предразмеченных датасетов, и в рамках проверки прокликать 1000 изображений можно за пару часов.
Но если ваша модель делает более сложные предсказания, например связанные с оптимизацией энергопотребления или графика движения поездов, то верификация модели будет достаточно трудоемкой задачей. Возьмем пример из области геопространственной аналитики. Предположим, существует модель, занимающаяся классификацией растений, вам нужно ответить, сколько в масштабах страны будет выращено риса. Для этого на основе информации ДЗЗ нужно сегментировать и классифицировать поля, которые используются для промышленного выращивания данной культуры (для этого можно использовать сторонние источники - земельные кадастры), затем провести классификацию растений, которые произрастают на этой территории. А потом с помощью различных методик, индексов NDVI и т.д. оценивать ход роста, развития, готовности к сбору культуры, уровень воды на проливных полях (для чего потребуется SAR) ну и как результат, потенциальный объем урожая на данный момент времени.
Предположим, вы сделали на основе аннотированных данных какую-то модель, далее вам нужно ее проверить. Что вам для этого потребуется? Опять же аннотированные данные, данные, проверенные людьми, причем иногда вручную, с физическим выездом на конкретное место, чтобы проверить, что ваша модель поддерживает все многообразие вариантов рисоводства на различных этапах жизненного цикла, и сбой классификации вызван не ошибкой модели, а предприимчивым агрономом, засеявшим центр поля "растением силы". Иногда, если не получается создать универсальную модель, то создаются переобученные (overfitted) модели под конкретные условия, для конкретного региона или ситуации. В этом случае разнообразие наборов тестовых данных возрастает.
Если вы сравниваете две модели, то они, естественно, должны работать на одних и тех же данных, в одних и тех же условиях. И в идеале производитель не должен знать, на каком датасете его будут тестировать, потому что, если модель будет обучаться на этих данных, то модель можно "подогнать" под эти данные, то есть на других данных она будет выдавать негарантированный результат. Встречались ситуации, когда производители в условиях подобного тестирования делали привязки тестовых данных к результатам, например зная свои ложные срабатывания на определенных тестовых данных, они добавили в продукт "ручные" фильтры, чтобы улучшить финальную точность. К сожалению, практика часто показывает, что заявляемые производителями параметры могут быть достигнуты только в лабораторных условиях.
Таким образом, когда требуется оценить эффективность разных моделей ИИ на разных данных и в различных условиях, требуется иметь еще несколько наборов аннотированных данных. Это может стоить, как минимум, половину тех денег, которые используются для подготовки обучающих данных. В этой ситуации затраты ложатся не только на разработчиков, но и на потребителей, которым требуется оценить конченый результат.
Никакого Ростеста или международной сертификации моделей пока нет и будет нескоро. Потребность очевидна и есть первые ласточки, такие как методика сравнения систем распознавание лиц или опять же, классификация котиков и собачек в интернете.
Здесь, в связи с профессиональной деформацией, приходит в голову аналогия с антивирусными тестовыми лабораториями, такими как AVTest, AV-Comparatives, поскольку они решают схожую задачу – определение ключевых метрик эффективности классификаторов, отделяющих вредоносное программное обеспечение от пока еще нет. Как правило, в бизнес-модели этих лабораторий есть "открытые" тесты, результаты которых публикуются вне зависимости от согласия производителя, а также приватные или полу-приватные, в рамках которых оцениваемый вендор имеет существенное влияние на методику и может получать дополнительную информацию, которая в дальнейшем может использоваться для развития продукта.
Замыкая круг
Еще один важный момент – это аккумуляция обратной связи. Все модели ИИ не идеальны, поэтому в рамках их жизненного цикла в реальных условиях им требуется человек, который будет контролировать, давать обратную связь по всем недостаткам их работы. В качестве примера возьмем тот же медицинский стартап, который наконец-то нашел себе первого заказчика, всеми правдами и неправдами внедрил систему на своем ноутбуке где-то под столом у главного радиолога, обучился и как-то синтегрировался с DICOM viewer-ом. После этого врачи начинают работать и первое, что они начинают выявлять – это ложные срабатывания. И они там будут, например 7% (причем врач при диагностике может допускать 14% и больше), но поскольку стартап для врача чужой, врачам будет приятно находить какие-то недостатки. И это отлично! Потому что недостатки, выявленные экспертом – это дополнительная аннотация, которую можно применить, чтобы улучшить модель.
Вопрос в том, что эту аннотацию нужно собирать в структурированном виде (иначе она останется бесполезными данными), где-то ее складировать, фильтровать и предоставлять к ней доступ. И после этого эта информация может использоваться как для оценки эффективности модели, так и для получения новых аннотированных данных, в конечном счете, для улучшения этой и других моделей. Опять же модно сейчас, semi supervised learning, active learning и прочие базворды.
Эрик Шмидт: Разумные машины. Применение искусственного интеллекта в нашем мире
А что у них?
В качестве хорошего и грамотного примера технической реализации возьмем NVIDIA CLARA Platform. Nvidia – это компания, которая в свое время разрабатывала видеокарты. Затем в момент подъема популярности Bitcoin и первой волны Deep Learning она первой сумела преобразовать свои видеокарты в высокопроизводительные процессоры GPGPU (General-purpose computing on graphics processing units). До этого считать хэши и перемножать матрицы было необходимо только криптологам, хакерам и геймерам, а тут.. Nvidia быстро сориентировалась, выпустила специализированные под эти задачи серверы - линейку Nvidia DGX. Но компания не остановилась на производстве техники и начала создавать программную инфраструктуру под ИИ. И эта инфраструктура создана под разработчиков, потому что если они работают на твоем железе и софте, то эти продукты будут востребованы, это коммерчески выгодная производителю связь клиента и разработчика. Как аналогию можно привести компанию Microsoft с их операционной системой и офисными продуктами. Мало кто хочет менять это ПО, так как под него много всего написано и просто привыкли. Сейчас Nvidia – это огромный набор систем и приложений, ориентированных на машинное обучение не только на родных, но и на других серверах. Давайте рассмотрим пример Nvidia Clara Platform.
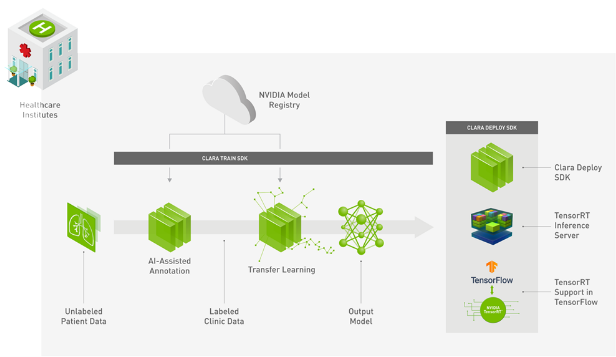
Рис.5. Архитектура NVIDIA Clara. Источник nvidia.com
С практической точки зрения Nvidia Clara Platform – это специализированный framework для полного цикла разработки программного обеспечения, области анализа медицинских изображений. Здесь и сбор, и аннотация, и обучение, и инференс (inference). Система ориентация на Linux с docker контейнерами, для управления используется Kubernetes, в качестве PACS применяется Orthanc и другие компоненты с открытым исходным кодом. И, что важно, Nvidia Clara работает на всех главных облачных хранилищах - "из коробки" поддерживаются облака Microsoft Azure, Google Compute Engine, Amazon AWS. Все это дает неоспоримые преимущества, поскольку нашему медицинскому стартапу не придется ломать голову над созданием инфраструктуры, а будет достаточно загрузить докеры в арендованное облако и начать работать. Без датацентра.
Собираем кубики
Вспомним жизненный цикл модели ИИ: сбор данных, предварительная обработка, сохранение и предоставление доступа к данным, с использованием специализированных для отраслей индустриальных стандартов и API, аннотация данных, обучение модели, анализ эффективности модели и обеспечение обратной связи. Вот задачи тех дата-центров, про которые сейчас так много говорят. Хотелось бы заметить, что дата-центров в этих задачах нет, то есть они, конечно, есть, но они где-то глубоко внизу, а на поверхность выходят задачи более высокого уровня оркестрации процессами с глубоким пониманием отраслевой специфики.
Таким образом, низовым техническим уровнем, на котором нужно сконцентрироваться, являются не дата-центры, которые физически уже есть в России, строить мы их уже научились, но облачные платформы.
Облачные платформы, как минимум, уровня Infrastructure as a Service, а лучше PaaS, являются тем необходимым базисом, на котором нужно сконцентрироваться на техническом уровне построения инфраструктуры ИИ в масштабах страны.
Я уверен, что у таких крупных вендоров как Яндекс и Mail.ru есть своя платформа, но на крайний случай есть OpenStack, который тоже иногда работает.
Именно подобные решения нужно масштабировать, нужно выбрать производителей и делать из них национальных лидеров в этой области. Пускай их будет, например два, это не плохо. Только с самого начала нужно договориться об API, особенно если речь идет про PaaS, с IaaS как правило все достаточно просто.
Далее стоит подумать над уровнем сбора данных (ingestion) и размещении их в data lake. Здесь необходимо работать унифицированно и централизованно. Централизованная работа в этом направлении нужна в том числе и с точки зрения производительности, которая на больших данных становится вопросом. В идеале, это должна быть команда, которая в плотном взаимодействии с отраслевыми группами будет работать с разнородными источниками данных, готовить коннекторы для загрузки информации в облако.
Следующий момент, это облачная платформа для хранения и обработки специализированных данных, таких как медицинские, геопространственные, биометрические и т.д. То есть у нас должен сложиться набор облачных "PACS-ов", а лучше платформ, аналогичных NVidia Clara. И это уже достаточно большая задача.
Это направление может создать свой рынок, поскольку при дальнейшем масштабном внедрении технологий подобные системы будут востребованы не только в "ИИ-облаке", они пойдут в каждую региональную организацию, которая будет работать с этой системой, в данной области по модели гибридного или частного облака. И это деньги, которые можно заработать на R&D, создании рабочих мест вместо того, чтобы отдавать отраслевым гигантам.
Быстрее, выше, сильнее
Давайте рассмотрим, как эта система может работать в случае нашего медицинского стартапа. Обратившись в условный "Фонд ИИ Сколково", они запрашивают доступ к данным интересующих их модальностей и нозологии, например КТ/НДКТ легких. Если подобные аннотированные данные уже присутствуют в системе, "Фонд" может предложить получить к ним доступ на определенных условиях. Это может быть открытая часть данных, доступная всем зарегистрированным организациям, либо приватные датасеты, распространяемые по подписке. При этом стоимость подписки может покрываться из субсидий или инвестиций "Фонда".
В дальнейшем наш стартап может продолжить работать в облачной среде, используя вычислительные мощности и хранилища. Принципы оплаты могут варьироваться от "денег на бочку" до условного депонирования наработанной интеллектуальной собственности (модели) "Фонду". Причем датацентр с "отечественными ИИ процессорами" может находиться далеко от хранилищ данных. Ведь для обучения требуется лишь ничтожная часть, например размеченные срезы с узелком, это пару десятков из примерно тысячи снимков НДКТ высокого разрешения (1 – 0,5 мм). Более того, несколько часов на загрузку датасета обычно ничего не значат по сравнению с временем обучения модели.
Если у стартапа не хватает исследовательских ресурсов, то в экосистеме, сложившейся вокруг наших "датацентров", можно найти научные организации, которые помогут с оптимизацией модели, поскольку эта задача подчас требует наличия узкоспециализированных специалистов, нанимать которых в штат на 2-3 месячный НИОКР не имеет смысла. Оплата их труда может варьироваться в зависимости от эксклюзивности результатов, и возможности их повторного использования в виде публикаций, кода и других артефактов.
По мере развития у стартапа будут поваляться свои датасеты, полученные в ходе верификации модели, тестирования приложений и других изысканий. Эти данные, после верификации, могут поступать в общее хранилище, снижая "задолженность" перед "Фондом" и увеличивая общее количество аннотированных данных, возможно, добавляя к ним новые фичи.
Затем стартап может обратиться к сервису оценки эффективности, который может быть реализован в виде автоматического сервиса, отрабатывающего на тестовых датасетах и выдающего ROC/AUC для заданных параметров и примеры ложноположительных и ложноотрицательных срабатываний. Для более сложных ситуаций могут привлекаться экспертные организации, работающие по модели "сравнения антивируса", описанной выше. И после серии "приватных" тестов можно участвовать в открытом тестированиии, получив рекламу в виде подтвержденных цифр, на которые может ориентироваться потребитель.
Вот о таких "датацентрах" мечтают наши Огромные Боевые Человекоподобные Роботы. Вот такие "датацентры" нам нужны!

Добавить 5 комментариев
Годный лонгрид на Роем, давно такого не было!
Из статьи можно сделать вывод, что в будущем власть должна быть в руках программистов, иначе тотальное отставание…
Программисты должны сделать ставку на открытость общества и гарантированный базовый доход, как плату за это. Европейский путь с политикой закрытых персональных данных России не по карману.
Если передавать власть только одной группе людей, даже очень хороших, последствия немного предсказуемы. Поскольку люди разные, интересы у всех разные, и взять и убить всех плохих людей — нельзя.
Так что я бы не делал такого вывода.
Иметь роскошь смотреть на последствия, могут себе позволить только экономические лидеры планеты. Они могут себя обвешать с головы до ног системами сдержек и противовесов.
Наша страна никогда не могла (и не сможет) себе позволить систему сдержек и противовесов, любая попытка обвешаться ими приводила всегда к одному — к краху.
Мы как страна обречены делать то, что может (будет) иметь отрицательные последствия, но необходимо для сиюминутного выживания здесь и сейчас.
Власть программистов неизбежна, иначе крах.
Тут логическая ошибка. Не может быть одновременно и «неизбежна», и «иначе». Если есть какое-то «иначе», то тогда ошибочно писать «неизбежна».
Вобщем вас, походу, в эту будущую власть программистов не возьмут …
«Неизбежно» это для реальности в которой еще существует Россия, в реальности где будет «иначе» России уже не будет.
«Иначе» существует всегда, логично ли это или нет.